
Uma das coisas mais importantes na web é ter visibilidade, mas mais importante ainda é conseguir isto de forma que seu conteúdo chegue ao público correto. Eu poderia começar a falar aqui de toda a bonita história da internet e de como tudo gradativamente está se tornando semântico na web, mas isto é assunto para o próximo post.
Desde a década de 1990, a W3C tem apresentado maneiras para definição de conteúdo semântico, e de lá pra cá surgiram outras alternativas, mas devido a grande quantidade de informações, falarei apenas um pouco sobre cada uma delas: RDF, RDFa, Microformats e Microdata ← focaremos neste último cara aqui.
Vale salientar que os principais motores de busca já levam em consideração o uso de qualquer uma destas tecnologias citadas (pelo menos em parte).
RDF (Resource Description Framework)
Criada pela W3C em 1999, é uma linguagem baseada em XML que foi concebida com o intuito de representar informação na internet. RDF é um modelo similar aos conceitos de modelagem Entidade-Relacionamento. RDF é tão abrangente que é possível definir linguagens para definição de ontologias com ela. Na minha opinião, usar RDF para marcar páginas web semanticamente hoje em dia é a mesma coisa que querer usar uma bala de canhão pra matar uma formiga. Na prática, principalmente por ser uma outra linguagem, RDF é um mundo tão grande e diferente que se torna complexo querer definir qualquer relacionamento semântico nos ambientes web conhecidos de hoje.
RDFa (RDF – in – attributes)
O título fala por si só. RDFa é a marcação semântica sem a necessidade de utilização de novos elementos de marcação, sendo feita usando atributos que podem ser embutidos em qualquer elemento. A grande vantagem que a difere de RDF é a possibilidade de marcação no próprio conteúdo (já que um RDF tem que residir em um arquivo separado – o que acaba com a duplicação de dados do RDF). Porém, RDFa foi desenvolvida como um conjunto de extensões de XHTML e obedecendo aos padrões XML, obrigando-nos a fazer uso de namespaces para todo e qualquer escopo/atributo de item semântico que quisermos descrever, tornando assim a marcação semântica um tanto chata e trabalhosa.
Microformats
Microformats não se trata de mais uma nova linguagem querendo abraçar o mundo. A idéia é resolver os problemas mais simples primeiro, adaptando-se aos padrões atuais e fazer com que você passe a usar uma marcação semântica o mais rápido possível, já que é de fácil utilização. A proposta dos microformats é bem simples e muito bem difundida. Dentre os formatos mais usados, estão o hCalendar (para publicação de eventos) e hCard (para pessoas, empresas e organizações em geral). Veja mais formatos definidos.
Microdata
Foi criado pelo WHATWG (os caras do HTML5/WebApplications 1.0) e tornou-se o padrão de marcação semântica adotado pelo HTML5. Microdata utiliza-se de variados vocabulários para descrever itens semanticamente e pares key-value para atribuição de valores a suas propriedades.
Ótimo, mas onde podemos encontrar esses tais vocabulários? Os primeiros vocabulários microdata foram definidos em 2010 e podem ser encontrados em data-vocabulary.org. Note que existem poucos vocabulários definidos (apenas 9), que são: Event, Organization, Person, Product, Review, Review-aggregate, Breadcrumb, Offer e Offer-aggregate. Mas calma lá, o melhor do microdata ainda está por vir com o Schema.org, um repositório de vocabulários microdata que cresce a cada dia.
Schema.org
Os principais motores de busca se baseiam nos vocabulários do schema.org para melhor indexar, classificar e refinar seus resultados de busca, visto que o schema.org é na verdade um consórcio entre os grandes buscadores da web – Google, Bing e Yahoo! – para “criar e suportar um grupo de esquemas em comum para dados de marcação estruturados em páginas web”. A iniciativa começou com um pequeno número de formatos (esquemas ou tipos), mas o objetivo a longo prazo é suportar uma ampla gama de formatos. No momento em que escrevo este post, já se encontram em torno de 450 formatos definidos no schema.org – Lista completa. Existem desde os tipos mais básicos como pessoa (Person), evento (Event) ou organização (Organization) até os mais específicos como dentista (Dentist), parada de ônibus (BusStop) e até mesmo templo hindu (HinduTemple).
Beleza, mas por que Microdata, e não o super-bombado RDF/RDFa? Abaixo coloquei uma pequena lista com as razões mais óbvias, que apenas traduzi deste post de Roy Tennant, com o qual concordo plenamente e também recomendo a leitura.
- Há um claro incentivo à utilização de microdata – Ao contrário de RDF, há um claro incentivo hoje para utilizar microdata em suas páginas web. As grandes armas estão por trás do microdata. Se você tivesse que nomear as maiores empresas da internet, é muito provável que o Google, Yahoo! e Microsoft estivessem nesta lista. Eles têm aparentemente ignorado RDF e RDFa em favor do Schema.org.
- Não há nenhuma razão clara para usar RDFa e não microdata – O que RDFa se propõe a fazer que microdata não? Comentem por favor =)
- É simples – Esta é a minha razão favorita. Sou um grande fã da simplicidade, especialmente quando se consegue um resultado tão (ou quase tão) bem feito de como se fosse algo mais complexo.
- Faz parte do padrão HTML5 (esta foi adicionada por mim =) - Aqui no Loop infinito nós encorajamos o uso dos padrões W3C, tanto que este blog já foi construído usando HTML5 e CSS3 desde o início.
Na prática
Existem vários serviços do Google, por exemplo, que fazem filtragens mais específicas de conteúdo e que levam muito em consideração a marcação semântica. Dois bons exemplos são o Google Shopping (busca de produtos à venda) e o Google Recipes (busca de receitas culinárias). É verdade que estes serviços conseguem recuperar também conteúdo não marcado semanticamente (a grande maioria), mas os que utilizam RDFa, microformats ou microdata têm chances muito maiores de serem os primeiros no pagerank.
No Google Shopping, fiz uma pesquisa simples por “jornalista” e eis o resultado obtido:
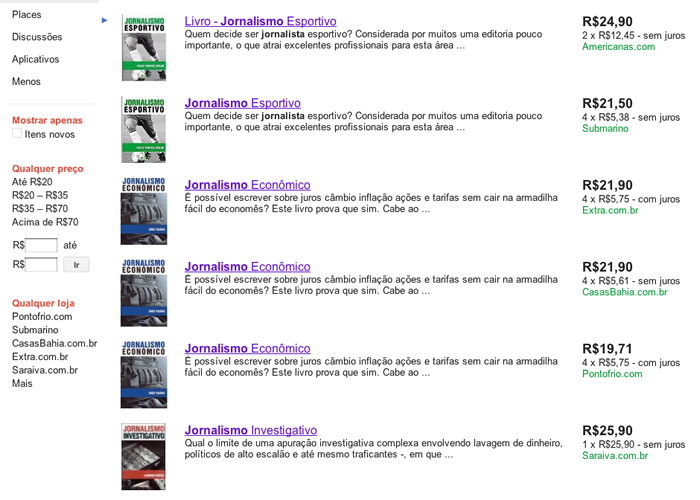
Pela imagem acima, é possível perceber que o nível de refinamento de uma pesquisa pode ser muito mais específico do que apenas procurar por palavras-chaves – como acontece normalmente hoje. Percebam que podemos especificar se procuramos por um produto novo ou não, a faixa de preço desejada e até a loja. Os seis primeiros resultados foram dos sites: Americanas.com, Submarino.com.br, Extra.com.br, CasasBahia.com.br, PontoFrio.com e Saraiva.com.br. Tive a curiosidade de analisar o código fonte de cada um deles, e eis que consegui detectar na base do olhômetro (se eu estiver errado sobre algum, por favor deixe um comentário):
- Americanas.com - usa microformats;
- Submarino.com.br - não usa marcação semântica;
- Extra.com.br - usa microformats;
- CasasBahia.com.br - usa microformats;
- PontoFrio.com - usa microformats;
- Saraiva.com.br - não usa marcação semântica.
No Google Recipes, pesquisei por “cupcake”:
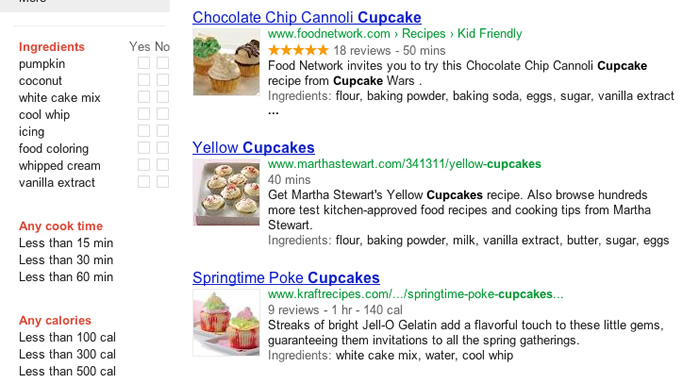
Novamente, reparem nos filtros disponíveis para receitas. Eles diferem dos de produtos (mostrados acima). Aqui é possível especificar o uso (ou não uso) de determinados ingredientes na receita (muito útil para quem tem alergia a certos alimentos, por exemplo), tempo de cozimento e até mesmo o valor calórico do que procuro. É outra história, meus amigos. Os três primeiros resultados foram dos sites: FoodNetwork.com, MarthaStewart.com e KraftRecipes.com. Analisando o código fontes das páginas, obtive que:
- FoodNetwork.com - usa microformats;
- MarthaStewart.com - usa microformats;
- KraftRecipes.com - usa RDFa;
Pondo a mão na massa
Apesar de não ter detectado o uso de microdata/schema.org nos exemplos acima, nós optamos por esta forma de marcação para aplicar aqui no Loop Infinito pelas mesmas razões que citei anteriormente.
No próximo post falarei mais detalhadamente sobre microdata e schema.org, e também explicarei detalhadamente como marcamos conteúdo HTML usando os vocabulários do schema.org. Até a próxima! o/